
Claude API Python 入门教程:从安装到流式输出,保姆级完整指南(2026)
没用过 Claude API?这篇从零开始——装好环境、发第一条消息、多轮对话、流式输出,每一步都有可直接运行的代码,全程不需要代理。
看完本文你将学会
- ✅ Anthropic Python SDK 安装与配置(含国内镜像加速)
- ✅ 发出第一条 API 请求(附真实终端截图)
- ✅ System Prompt 角色设定,让 AI 变成你的专属工程师
- ✅ 多轮上下文对话(三轮实测,截图逐轮演示)
- ✅ 流式输出实现打字机效果(Streaming)
- ✅ FastAPI 集成 SSE 实时推流(前后端完整代码)
- ✅ 生产环境错误处理与最佳实践
所有代码均在本地实测跑通,截图为真实终端运行结果,可直接复制使用。
目录
- 环境准备
- 第一步:安装 Anthropic SDK
- 第二步:发出第一条消息
- 第三步:System Prompt 设定 AI 角色
- 第四步:实现多轮对话
- 第五步:流式输出 Streaming
- 第六步:FastAPI 集成 SSE 推流
- 第七步:生产环境错误处理
- 模型选型参考
- 常见问题 FAQ
环境准备
开始前确认两件事:Python ≥ 3.8,pip 可用。
# 确认 Python 版本
python --version
# 确认 pip 可用
pip --version
# 确认 Python 版本
python --version
# 确认 pip 可用
pip --version
还需要一个 Claude API Key。国内开发者推荐去 ClaudeAPI.com 注册:国内直连,不需要科学上网,注册即送体验额度,5 分钟内跑通第一个请求。
第一步:安装 Anthropic SDK
pip install anthropic
pip install anthropic
验证安装成功:
python -c "import anthropic; print(anthropic.__version__)"
# 输出示例:0.40.0
python -c "import anthropic; print(anthropic.__version__)"
# 输出示例:0.40.0
国内网络慢可换清华源:
pip install anthropic -i https://pypi.tuna.tsinghua.edu.cn/simplepip install anthropic -i https://pypi.tuna.tsinghua.edu.cn/simple
第二步:发出第一条消息
新建 hello_claude.py,写入以下代码:
import os
import anthropic
# 清除系统残留代理变量,避免 SSL 冲突
os.environ['HTTP_PROXY'] = ''
os.environ['HTTPS_PROXY'] = ''
os.environ['ALL_PROXY'] = ''
os.environ['http_proxy'] = ''
os.environ['https_proxy'] = ''
os.environ['all_proxy'] = ''
client = anthropic.Anthropic(
api_key="your-api-key-here", # 替换成你的 Key
base_url="https://api.claudeapi.com", # 国内直连节点,无需代理
timeout=60.0,
)
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[
{"role": "user", "content": "用一句话解释什么是递归"}
]
)
print(message.content[0].text)
import os
import anthropic
# 清除系统残留代理变量,避免 SSL 冲突
os.environ['HTTP_PROXY'] = ''
os.environ['HTTPS_PROXY'] = ''
os.environ['ALL_PROXY'] = ''
os.environ['http_proxy'] = ''
os.environ['https_proxy'] = ''
os.environ['all_proxy'] = ''
client = anthropic.Anthropic(
api_key="your-api-key-here", # 替换成你的 Key
base_url="https://api.claudeapi.com", # 国内直连节点,无需代理
timeout=60.0,
)
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[
{"role": "user", "content": "用一句话解释什么是递归"}
]
)
print(message.content[0].text)
运行:
python hello_claude.py
python hello_claude.py

图1:第二步运行截图 — Claude 回答「什么是递归」,并给出阶乘函数示例
注意:
max_tokens是必填项,这是 Claude API 与 OpenAI 最大的参数差异,不填直接 422 报错,给1024够用。
第三步:System Prompt 设定 AI 角色
System Prompt 决定 AI 的角色和行为。Claude 的 system 是独立的顶层参数,不能像 OpenAI 那样塞进 messages 数组。
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system="你是资深 Python 工程师,代码风格简洁,回答直接不废话,必须给出可运行示例",
messages=[
{"role": "user", "content": "怎么读取大文件不撑爆内存?"}
]
)
print(message.content[0].text)
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system="你是资深 Python 工程师,代码风格简洁,回答直接不废话,必须给出可运行示例",
messages=[
{"role": "user", "content": "怎么读取大文件不撑爆内存?"}
]
)
print(message.content[0].text)
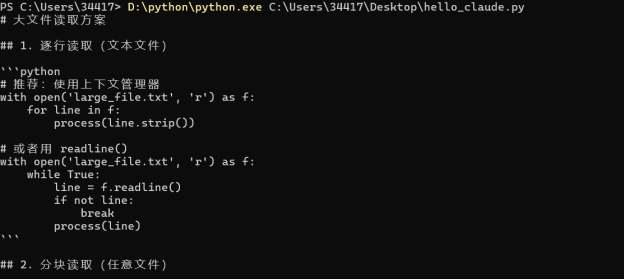
图2:System Prompt 生效 — AI 以 Python 工程师身份给出逐行读取、分块读取方案
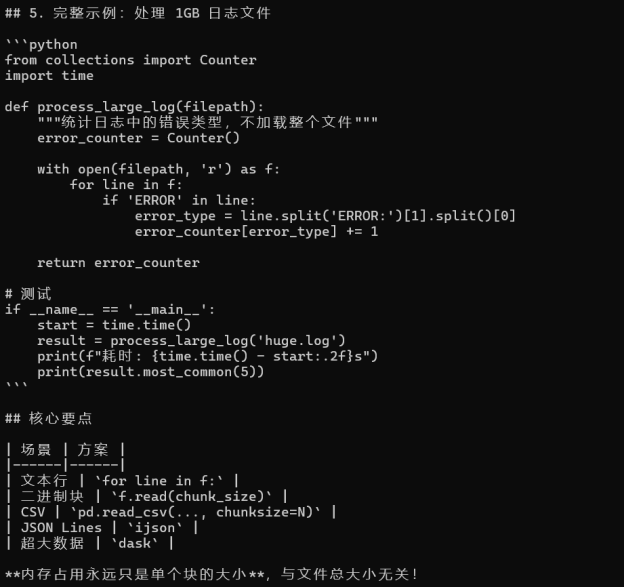
图3:AI 继续输出完整处理大日志文件的实战代码,并附最优方案总结
System Prompt 写作技巧
| 技巧 | 示例写法 | 效果 |
|---|---|---|
| 指定角色身份 | 你是资深 XX 工程师 |
回答更专业,贴近实际场景 |
| 明确输出格式 | 只输出代码,不要解释 |
减少废话,精准输出 |
| 限定回答风格 | 回答精简,不超过 100 字 |
控制长度,便于快速消费 |
| 约束语言框架 | 用 Python 3.10+ 语法 |
避免过时写法 |
| 设定禁止行为 | 不要道歉,不要说「当然」 |
减少客套话,直接给结果 |
第四步:实现多轮对话
Claude API 本身无状态,多轮对话需要手动把历史消息每次一起传进去。规则只有一条:user 和 assistant 必须严格交替。
history = []
def chat(user_input: str) -> str:
history.append({"role": "user", "content": user_input})
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system="你是专业代码助手",
messages=history,
)
reply = response.content[0].text
history.append({"role": "assistant", "content": reply})
return reply
print("=== 第一轮 ===")
print(chat("帮我写一个计算斐波那契数列的函数"))
print("\n=== 第二轮 ===")
print(chat("改成支持缓存的版本,避免重复计算"))
print("\n=== 第三轮 ===")
print(chat("再加上输入校验,负数要抛异常"))
history = []
def chat(user_input: str) -> str:
history.append({"role": "user", "content": user_input})
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system="你是专业代码助手",
messages=history,
)
reply = response.content[0].text
history.append({"role": "assistant", "content": reply})
return reply
print("=== 第一轮 ===")
print(chat("帮我写一个计算斐波那契数列的函数"))
print("\n=== 第二轮 ===")
print(chat("改成支持缓存的版本,避免重复计算"))
print("\n=== 第三轮 ===")
print(chat("再加上输入校验,负数要抛异常"))
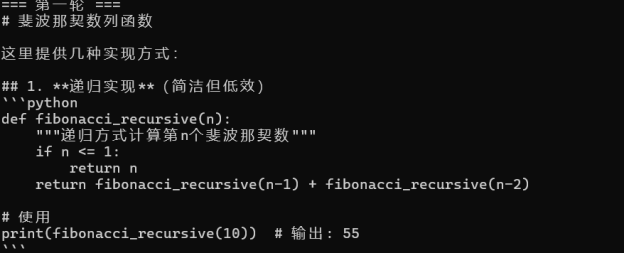
图4:第一轮对话 — Claude 提供斐波那契递归函数,附多种实现方式
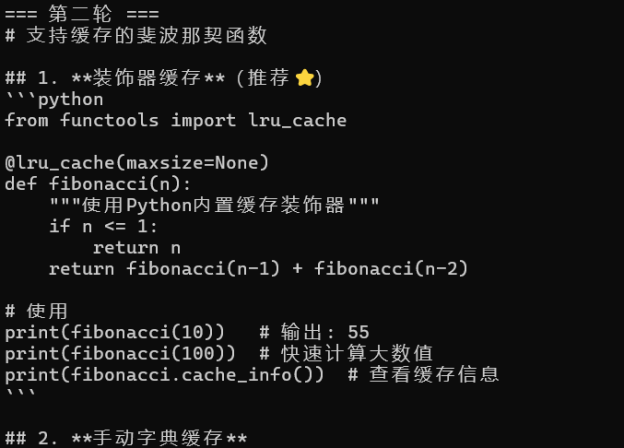
图5:第二轮对话 — AI 在上轮基础上添加
lru_cache缓存装饰器
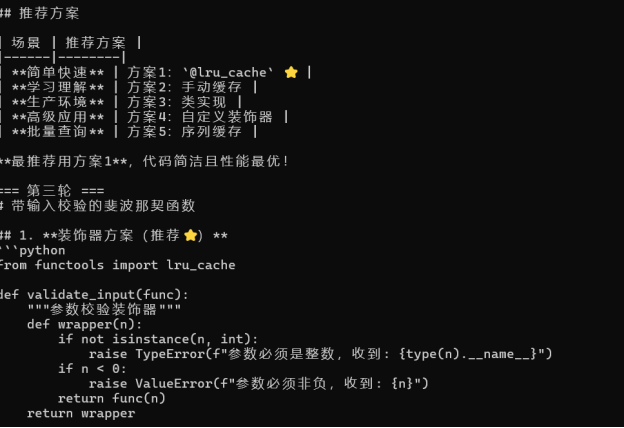
图6:第三轮对话 — AI 持续叠加功能,添加
validate_input参数校验装饰器
历史长度管理(防止 Token 超限)
对话轮数增多时 Token 消耗线性增长,加个截断保护:
MAX_HISTORY = 20 # 最多保留最近 20 条消息
def chat(user_input: str) -> str:
history.append({"role": "user", "content": user_input})
trimmed = history[-MAX_HISTORY:] if len(history) > MAX_HISTORY else history
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=trimmed,
)
reply = response.content[0].text
history.append({"role": "assistant", "content": reply})
return reply
MAX_HISTORY = 20 # 最多保留最近 20 条消息
def chat(user_input: str) -> str:
history.append({"role": "user", "content": user_input})
trimmed = history[-MAX_HISTORY:] if len(history) > MAX_HISTORY else history
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=trimmed,
)
reply = response.content[0].text
history.append({"role": "assistant", "content": reply})
return reply
第五步:流式输出 Streaming
默认调用等 AI 生成完才一次性返回。流式输出让内容边生成边显示,实现打字机效果,大幅提升用户体验。
基础流式输出
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[
{"role": "user", "content": "用 Python 实现冒泡排序算法,逐行注释代码"}
],
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
print("\n\n输出结束")
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[
{"role": "user", "content": "用 Python 实现冒泡排序算法,逐行注释代码"}
],
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
print("\n\n输出结束")

图7:流式输出实时效果 — 冒泡排序代码边生成边打印,打字机体验
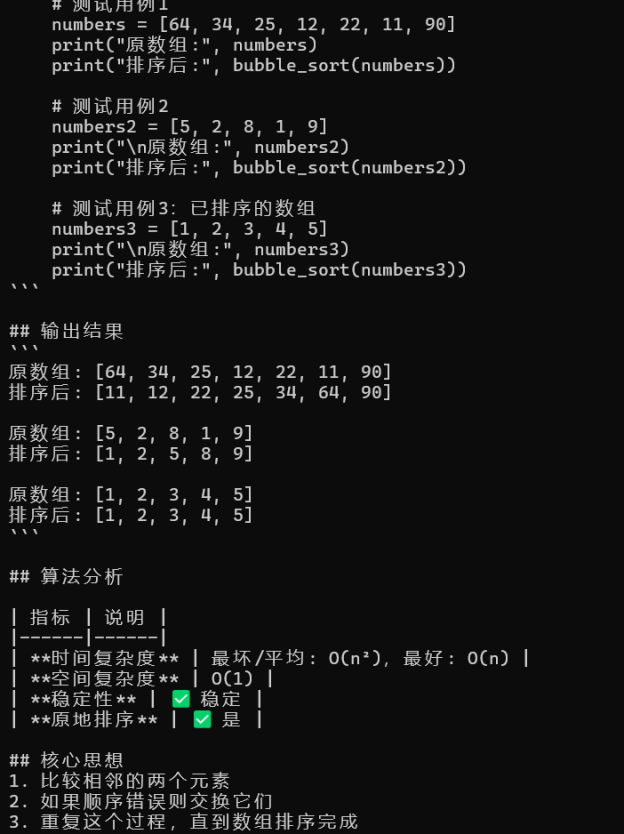
图8:流式输出完整结果 — 排序验证用例与算法分析一并输出
流式输出 + 获取 Token 用量
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "用 Python 实现冒泡排序算法,逐行注释代码"}],
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
final = stream.get_final_message()
print(f"\n\nToken 消耗:输入 {final.usage.input_tokens},输出 {final.usage.output_tokens}")
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "用 Python 实现冒泡排序算法,逐行注释代码"}],
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
final = stream.get_final_message()
print(f"\n\nToken 消耗:输入 {final.usage.input_tokens},输出 {final.usage.output_tokens}")

图9:加入 Token 统计后的流式输出 — 本次消耗输入 26、输出 918 个 Token
第六步:FastAPI 集成 SSE 推流
前端打字机效果,后端 SSE 实时推送,生产环境最常见的方案。
安装依赖:
pip install fastapi uvicorn
pip install fastapi uvicorn
后端代码(保存为 main.py):
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
import anthropic, os
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], allow_methods=["*"], allow_headers=["*"]
)
client = anthropic.Anthropic(
api_key="your-api-key-here",
base_url="https://api.claudeapi.com",
timeout=60.0,
)
@app.get("/chat")
async def chat_stream(q: str, system: str = "你是专业助手"):
def generate():
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=2048,
system=system,
messages=[{"role": "user", "content": q}],
) as stream:
for text in stream.text_stream:
yield f"data: {text}\n\n"
yield "data: [DONE]\n\n"
return StreamingResponse(
generate(),
media_type="text/event-stream",
headers={"X-Accel-Buffering": "no"},
)
# 启动命令
# uvicorn main:app --reload --port 8000
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
import anthropic, os
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], allow_methods=["*"], allow_headers=["*"]
)
client = anthropic.Anthropic(
api_key="your-api-key-here",
base_url="https://api.claudeapi.com",
timeout=60.0,
)
@app.get("/chat")
async def chat_stream(q: str, system: str = "你是专业助手"):
def generate():
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=2048,
system=system,
messages=[{"role": "user", "content": q}],
) as stream:
for text in stream.text_stream:
yield f"data: {text}\n\n"
yield "data: [DONE]\n\n"
return StreamingResponse(
generate(),
media_type="text/event-stream",
headers={"X-Accel-Buffering": "no"},
)
# 启动命令
# uvicorn main:app --reload --port 8000
前端接收(JavaScript):
const source = new EventSource(
`/chat?q=${encodeURIComponent('用Python实现冒泡排序')}`
);
source.onmessage = (event) => {
if (event.data === '[DONE]') { source.close(); return; }
document.getElementById('output').textContent += event.data;
};
source.onerror = () => source.close();
const source = new EventSource(
`/chat?q=${encodeURIComponent('用Python实现冒泡排序')}`
);
source.onmessage = (event) => {
if (event.data === '[DONE]') { source.close(); return; }
document.getElementById('output').textContent += event.data;
};
source.onerror = () => source.close();
关键配置:
X-Accel-Buffering: no防止 Nginx 等反代缓冲 SSE 响应,否则内容会积攒后一次性发出,打字机效果失效。
第七步:生产环境错误处理
上线前必须做的三件事:环境变量管理(Key 不硬编码)、自动重试(SDK 内置)、错误分类捕获。
标准生产配置
import anthropic, os
client = anthropic.Anthropic(
api_key=os.environ["ANTHROPIC_API_KEY"],
base_url=os.environ.get("ANTHROPIC_BASE_URL", "https://api.claudeapi.com"),
max_retries=3, # 自动处理 429 和 5xx,内置指数退避
timeout=60.0,
)
def chat(prompt: str, system: str = "") -> str:
kwargs = {
"model": "claude-sonnet-4-6",
"max_tokens": 2048,
"messages": [{"role": "user", "content": prompt}],
}
if system:
kwargs["system"] = system
try:
response = client.messages.create(**kwargs)
return response.content[0].text
except anthropic.AuthenticationError:
raise ValueError("API Key 无效,请检查环境变量")
except anthropic.RateLimitError as e:
raise RuntimeError(f"超出速率限制:{e}") from e
except anthropic.BadRequestError as e:
raise ValueError(f"请求参数错误:{e}") from e
except anthropic.APIStatusError as e:
raise RuntimeError(f"API 错误 {e.status_code}:{e.message}") from e
import anthropic, os
client = anthropic.Anthropic(
api_key=os.environ["ANTHROPIC_API_KEY"],
base_url=os.environ.get("ANTHROPIC_BASE_URL", "https://api.claudeapi.com"),
max_retries=3, # 自动处理 429 和 5xx,内置指数退避
timeout=60.0,
)
def chat(prompt: str, system: str = "") -> str:
kwargs = {
"model": "claude-sonnet-4-6",
"max_tokens": 2048,
"messages": [{"role": "user", "content": prompt}],
}
if system:
kwargs["system"] = system
try:
response = client.messages.create(**kwargs)
return response.content[0].text
except anthropic.AuthenticationError:
raise ValueError("API Key 无效,请检查环境变量")
except anthropic.RateLimitError as e:
raise RuntimeError(f"超出速率限制:{e}") from e
except anthropic.BadRequestError as e:
raise ValueError(f"请求参数错误:{e}") from e
except anthropic.APIStatusError as e:
raise RuntimeError(f"API 错误 {e.status_code}:{e.message}") from e
.env 文件(加入 .gitignore,绝对不要提交 git):
ANTHROPIC_API_KEY=your-api-key-here
ANTHROPIC_BASE_URL=https://api.claudeapi.com
ANTHROPIC_API_KEY=your-api-key-here
ANTHROPIC_BASE_URL=https://api.claudeapi.com
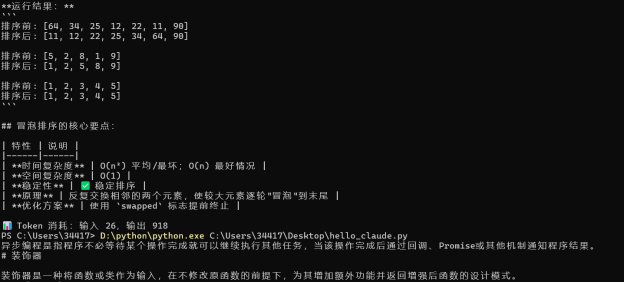
图10:生产配置下程序稳定运行 — 支持任意提问类型,Token 统计正常
错误码速查
| 状态码 | 含义 | 处理方式 |
|---|---|---|
| 401 | API Key 无效 | 检查环境变量中的 Key 是否正确 |
| 400/422 | 参数格式错误 | 检查 max_tokens(必填)、messages 格式 |
| 403 | 无权限访问该模型 | 确认账号权限级别 |
| 429 | 超出速率限制 | SDK 已内置自动重试,或升级额度套餐 |
| 529 | 服务过载 | 短暂等待后 SDK 自动重试 |
模型选型参考
| 模型 ID | 适合场景 | 速度 | 成本 |
|---|---|---|---|
claude-haiku-4-5-20251001 |
分类、翻译、摘要、简单问答、周报生成 | 最快 | 最低 |
claude-sonnet-4-6 |
代码生成、写作、分析,日常开发首选 | 快 | 中等 |
claude-opus-4-6 |
复杂推理、高难度任务、长文档理解 | 较慢 | 最高 |
claude-opus-4-7 |
复杂推理、高难度任务、长文档理解,Opus 最新版本 | 较慢 | 最高 |
建议:原型阶段统一用
claude-haiku-4-5-20251001省成本,效果验证后按需切换 Sonnet 或 Opus。
常见问题 FAQ
Q:max_tokens 必须设置吗?
必须。Claude API 不填直接 422 报错,这和 OpenAI(可选)不同。不知道填多少给 1024,长任务给 4096。
Q:system 为什么不能放在 messages 里?
Anthropic 原生 SDK 的设计如此,system 是顶层独立参数。用 OpenAI 兼容接口(/v1/chat/completions)则可以保留 role:system 写法,两种方式 ClaudeAPI.com 都支持。
Q:多轮对话 Token 越来越多怎么办?
限制历史长度(保留最近 N 条),见第四步的 MAX_HISTORY 截断方案。或定期用 Claude 对历史做摘要压缩,再把摘要替换原历史。
Q:流式输出中途断了怎么处理?
在迭代中捕获 anthropic.APIConnectionError,根据业务决定是否重试,或返回已收到的部分内容。生产环境建议加断线重连逻辑。
Q:OpenAI SDK 能直接调用 Claude API 吗?
可以。ClaudeAPI.com 完全兼容 OpenAI Chat 格式,只需把 base_url 和 api_key 换掉,model 改成 claude-sonnet-4-6,其余代码一行不动。
Q:国内调用有时候超时,怎么处理?
换 base_url 为 ClaudeAPI.com 国内直连节点即可,官方 api.anthropic.com 在国内连接不稳定,中转节点平均延迟 < 200ms,已有 10000+ 开发者在用。
总结
| 步骤 | 核心内容 |
|---|---|
| 安装 | pip install anthropic |
| 基础调用 | client.messages.create(),max_tokens 必填 |
| 角色设定 | 顶层 system 参数,不塞进 messages |
| 多轮对话 | 手动维护 history 列表,user/assistant 严格交替 |
| 流式输出 | client.messages.stream(),打字机效果 |
| Web 集成 | FastAPI + SSE,前后端完整代码 |
| 生产加固 | 环境变量 + max_retries + 分类错误处理 |
国内开发者直接跑这套代码,把 base_url 指向 ClaudeAPI.com 即可,不需要任何代理配置:
client = anthropic.Anthropic(
api_key="your-claudeapi-key",
base_url="https://api.claudeapi.com", # 只改这一行,其余代码不动
)
client = anthropic.Anthropic(
api_key="your-claudeapi-key",
base_url="https://api.claudeapi.com", # 只改这一行,其余代码不动
)
ClaudeAPI.com 支持 Anthropic 原生格式与 OpenAI 兼容格式,全系列 Claude 模型随时可用,人民币按需充值,注册即送体验额度。
注册地址:claudeapi.com — 5 分钟跑通第一个请求
相关阅读
- Claude API 报错完全手册:401/429/529 解决方案 →
- Claude Code 国内接入教程:cc-switch 一键切换 API 配置 →
- 用 Claude API 自动写周报:输入关键词 10 秒输出完整周报 →
本文由 ClaudeAPI.com 团队撰写,持续更新维护。最后更新:2026-04


