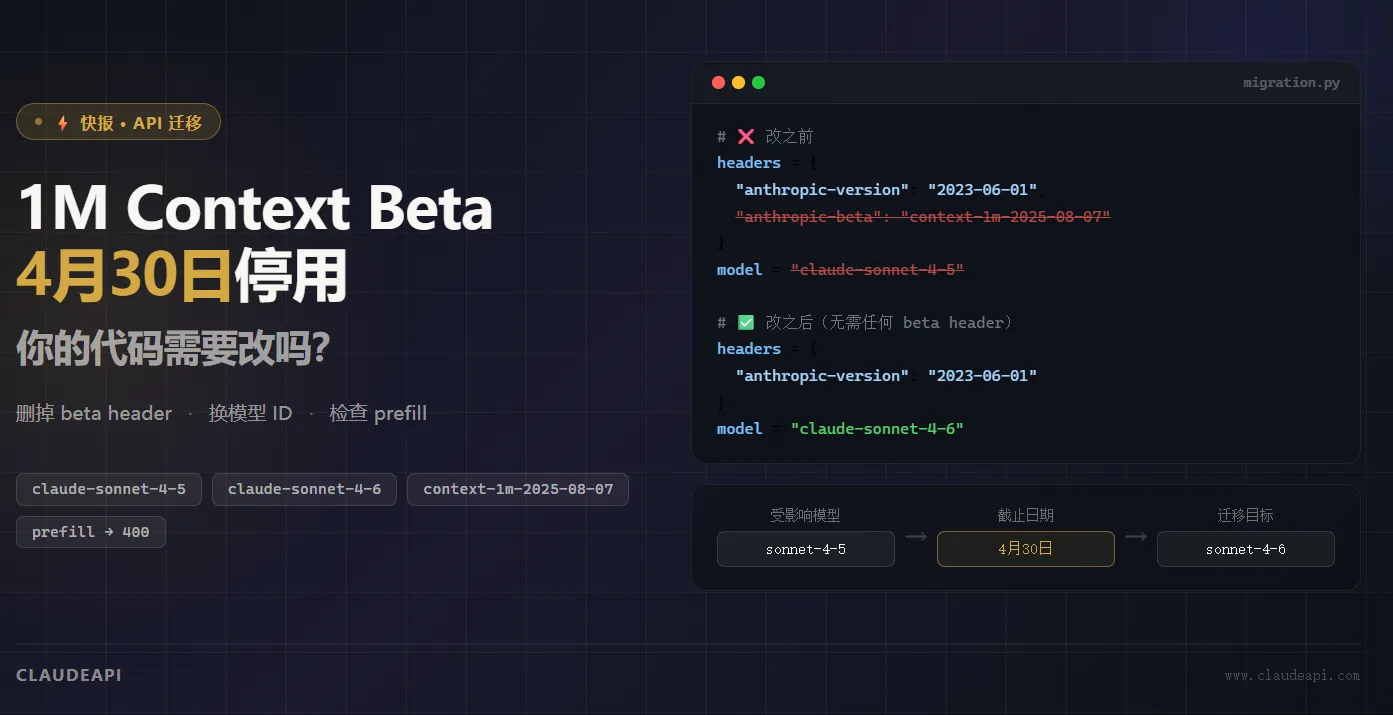
4月30日截止:Claude 1M Context Beta 停用,你的代码需要改吗?
结论先说: 如果你的代码里有 anthropic-beta: context-1m-2025-08-07 这行请求头,4月30日之后超过 200K Token 的请求将直接报错。迁移只需两步,但有一个隐藏的破坏性变更很多人没注意到。
发生了什么
Anthropic 将于 2026年4月30日 正式停用 context-1m-2025-08-07 beta header。
这个 header 是去年8月随 Claude Sonnet 4 一同推出的临时机制,让开发者可以提前体验 1M token 的超长上下文。现在,Anthropic 认为它已经完成历史使命——因为 Claude Sonnet 4.6 和 Claude Opus 4.6 早在今年2月就已原生支持 1M 上下文,不再需要任何 beta 开关。
退役通知于3月30日写入官方 changelog,距截止日期有30天窗口。但据技术媒体 Riptide Insights 的分析,很多团队已经习惯性地忽略 changelog 更新,直到现在才意识到这件事。
哪些 Claude API 用户受影响
对照以下清单,满足任意一条就需要读下去:
- 代码中使用了
anthropic-beta: context-1m-2025-08-07请求头 - 正在调用
claude-sonnet-4-5或claude-sonnet-4(旧版 ID:claude-sonnet-4-20250514) - 在 Amazon Bedrock 或 Google Cloud Vertex AI 上使用了上述模型 + 该 beta header
不受影响的情况: 如果你已经在用 claude-sonnet-4-6、claude-opus-4-6 或更新的模型,上下文限制早就是 1M token 标准配置,什么都不需要改。
迁移方法:两步搞定
绝大多数情况下,迁移就是两行代码的事。
Step 1:删掉 beta header
# 改之前
headers = {
"x-api-key": "YOUR_API_TOKEN",
"anthropic-version": "2023-06-01",
"anthropic-beta": "context-1m-2025-08-07", # ← 删掉这行
"content-type": "application/json"
}
# 改之后
headers = {
"x-api-key": "YOUR_API_TOKEN",
"anthropic-version": "2023-06-01",
"content-type": "application/json"
}
# 改之前
headers = {
"x-api-key": "YOUR_API_TOKEN",
"anthropic-version": "2023-06-01",
"anthropic-beta": "context-1m-2025-08-07", # ← 删掉这行
"content-type": "application/json"
}
# 改之后
headers = {
"x-api-key": "YOUR_API_TOKEN",
"anthropic-version": "2023-06-01",
"content-type": "application/json"
}
Step 2:更新模型 ID
# 旧模型 ID(停用后不再支持 1M context)
model = "claude-sonnet-4-5"
# 或
model = "claude-sonnet-4-20250514"
# 改为 Sonnet 4.6
model = "claude-sonnet-4-6"
# 旧模型 ID(停用后不再支持 1M context)
model = "claude-sonnet-4-5"
# 或
model = "claude-sonnet-4-20250514"
# 改为 Sonnet 4.6
model = "claude-sonnet-4-6"
使用 Anthropic 官方 SDK 的完整写法:
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_TOKEN")
response = client.messages.create(
model="claude-sonnet-4-6", # 更新模型 ID
max_tokens=8192,
messages=[{"role": "user", "content": "你的超长文档内容..."}]
# 无需任何 beta header,1M context 已是默认值
)
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_TOKEN")
response = client.messages.create(
model="claude-sonnet-4-6", # 更新模型 ID
max_tokens=8192,
messages=[{"role": "user", "content": "你的超长文档内容..."}]
# 无需任何 beta header,1M context 已是默认值
)
通过 ClaudeAPI 中转接入的用法完全一致,只需将 base_url 指向 https://gw.claudeapi.com 即可。具体接入方式参考 ClaudeAPI 接入教程。
⚠️ 隐藏破坏性变更:prefill 报错
这里有一个容易踩的坑,官方文档写了但很多人没注意到。
Claude Sonnet 4.6 不再支持 assistant 消息预填充(prefill)。
什么是 prefill?就是在 messages 数组里用 "role": "assistant" 预先填入一段内容,引导模型按特定格式输出。这是老版本常见的技巧:
# 这种写法在 Sonnet 4.5 上没问题
messages = [
{"role": "user", "content": "请输出 JSON 格式的结果"},
{"role": "assistant", "content": "{"} # ← prefill,引导模型以 { 开头
]
# 换到 Sonnet 4.6 后,这条请求会返回 400 错误
# 这种写法在 Sonnet 4.5 上没问题
messages = [
{"role": "user", "content": "请输出 JSON 格式的结果"},
{"role": "assistant", "content": "{"} # ← prefill,引导模型以 { 开头
]
# 换到 Sonnet 4.6 后,这条请求会返回 400 错误
如何修复? 有三种替代方案:
-
Structured Outputs(推荐):使用
output_config.format参数直接指定输出格式,比 prefill 更可靠 -
System Prompt 约束:在系统提示词中明确要求输出格式,例如「请严格以 JSON 格式输出,不要包含任何额外说明」
-
Prompt 改写:在 user 消息中直接说明格式要求
如果你的代码库里有大量 prefill 用法,Anthropic 在 Claude Code 中提供了 /claude-api migrate 命令,可以自动扫描并替换。
迁移到 Sonnet 4.6:能力和价格对比
从 Sonnet 4.5 迁移到 Sonnet 4.6,除了破坏性变更要处理,其余都是好消息:
| 对比项 | claude-sonnet-4-5 | claude-sonnet-4-6 |
|---|---|---|
| 1M Context | 需 beta header | ✅ 原生支持,无需 header |
| 价格(输入/输出) | $3 / $15 per MTok | $3 / $15 per MTok(不变) |
| SWE-bench 编码能力 | — | 79.6%(提升)[^1] |
| prefill 支持 | ✅ 支持 | ❌ 不支持(需改代码) |
| Prompt Cache | ✅ 支持 | ✅ 支持,最高省 90% |
| Batch API 折扣 | ✅ 50% | ✅ 50% |
价格没有变化,性能有提升,唯一的代价是处理 prefill 的兼容问题。对于大多数应用来说,这是值得的。
[^1]: SWE-bench 数据来自 NxCode 技术媒体对 Sonnet 4.6 的评测报告(2026年2月),官方页面未直接列出该数字,使用前请核实。
如果对价格敏感,建议同时了解一下 Prompt Caching 的使用方式,在超长上下文场景下最高可省 90% 的费用。详情参考 Claude API 价格完全指南。
常见问题
Q:4月30日之后,用旧模型 ID 调用会完全不能用吗?
模型本身(claude-sonnet-4-5)不会下线,还可以正常调用,只是超过 200K token 的请求会报错。如果你的应用不涉及超长上下文,旧模型 ID 暂时还能用——但建议尽早迁移,避免后续其他问题。
Q:Bedrock 和 Vertex AI 用户怎么处理?
据 Riptide Insights 报道,两个平台的 inference profile 配置如果包含该 beta header,同样会受影响,需要在对应平台的配置页面删除该 header。具体操作建议参考各平台官方文档。
Q:迁移之后,已有的 Prompt Cache 缓存还有效吗?
缓存是与模型 ID 绑定的,换了模型 ID 之后缓存会失效,需要重新建立。第一次请求会有缓存未命中的费用,之后恢复正常。
如果在迁移过程中遇到报错,可以参考 Claude API 报错完全手册 排查常见问题。
迁移完成后,通过 ClaudeAPI 控制台即可确认新模型是否正常调用:console.claudeapi.com。
本文由 ClaudeAPI 团队出品。


